1. LLM wiki의 개념
(1) LLM wiki의 목적
LLM 위키는 개인의 지식 관리(PKM)와 인공지능을 결합하여 '나만의 맞춤형 AI 비서 및 지식 베이스'를 구축하는 것을 목적으로 합니다. 사실 개인적으로도 "머신러닝 지식을 .md의 마크다운 파일로 분절시킨 뒤에 그 chunk들을 llm에 주입시키면 어떨까?", "개념 간의 관계를 graph를 이용해서 연결시키면 어떨까?"와 같은 생각을 했었는데, 역시 이러한 생각을 먼저 구체화시킨 능력자들이 있었습니다.
OpenAI의 공동창업자였던 Andrej Karpathy가 말하는 “LLM Wiki” 혹은 “LLM 기반 지식 위키”의 목적은 단순한 검색 시스템(RAG)을 넘어서, LLM이 지속적으로 축적·정제·연결하는 개인/조직의 장기 기억(long-term memory system) 을 만드는 데 있습니다.
(2) 기존 RAG의 한계점
기존 RAG는 문서를 chunk로 나눠 저장하고 질문할 때마다 관련 chunk를 다시 검색하며 매번 즉석으로 답변을 생성합니다. 다시 말해, 매 질의마다 “원문”을 다시 읽어야 하고 이전에 얻은 통찰이 구조화되어 남지 않으며 지식이 누적(compound)되지 않습니다. Karpathy는 정보를 단순 저장하는 것이 아니라 LLM이 이해 가능한 형태로 정리·연결하고 시간이 지날수록 더 똑똑해지는 “지식 시스템”을 만들어야 한다고 말합니다.
(3) 운영체제로서의 LLM
카파시는 LLM을 단순 챗봇이 아니라 “새로운 운영체제(OS)의 kernel process”처럼 봐야한다고 말했습니다. 이 관점에서 중요한 문제는 LLM은 기본적으로 stateless하며 세션이 끝나면 기억이 사라지는데다 긴 프로젝트 컨텍스트 유지가 어렵다는 것입니다.
LLM Wiki는 이를 해결하기 위해 A.markdown 기반 위키, B.entity/relationship 구조, C.링크 기반 지식 그래프, D.요약 및 정제된 페이지 구조를 유지합니다.
2. LLM wiki 구축
(1) Obsidian 설치
옵시디언(Obsidian)은 모든 메모를 로컬 PC의 마크다운(Markdown) 파일로 저장합니다. 클로드 코드(Claude Code)는 터미널(CLI) 환경에서 로컬 파일 시스템을 직접 읽고 쓸 수 있는 AI 도구입니다. 이 둘의 결합은 복잡한 서버 구축 없이도 AI 지식 베이스를 만들어냅니다.
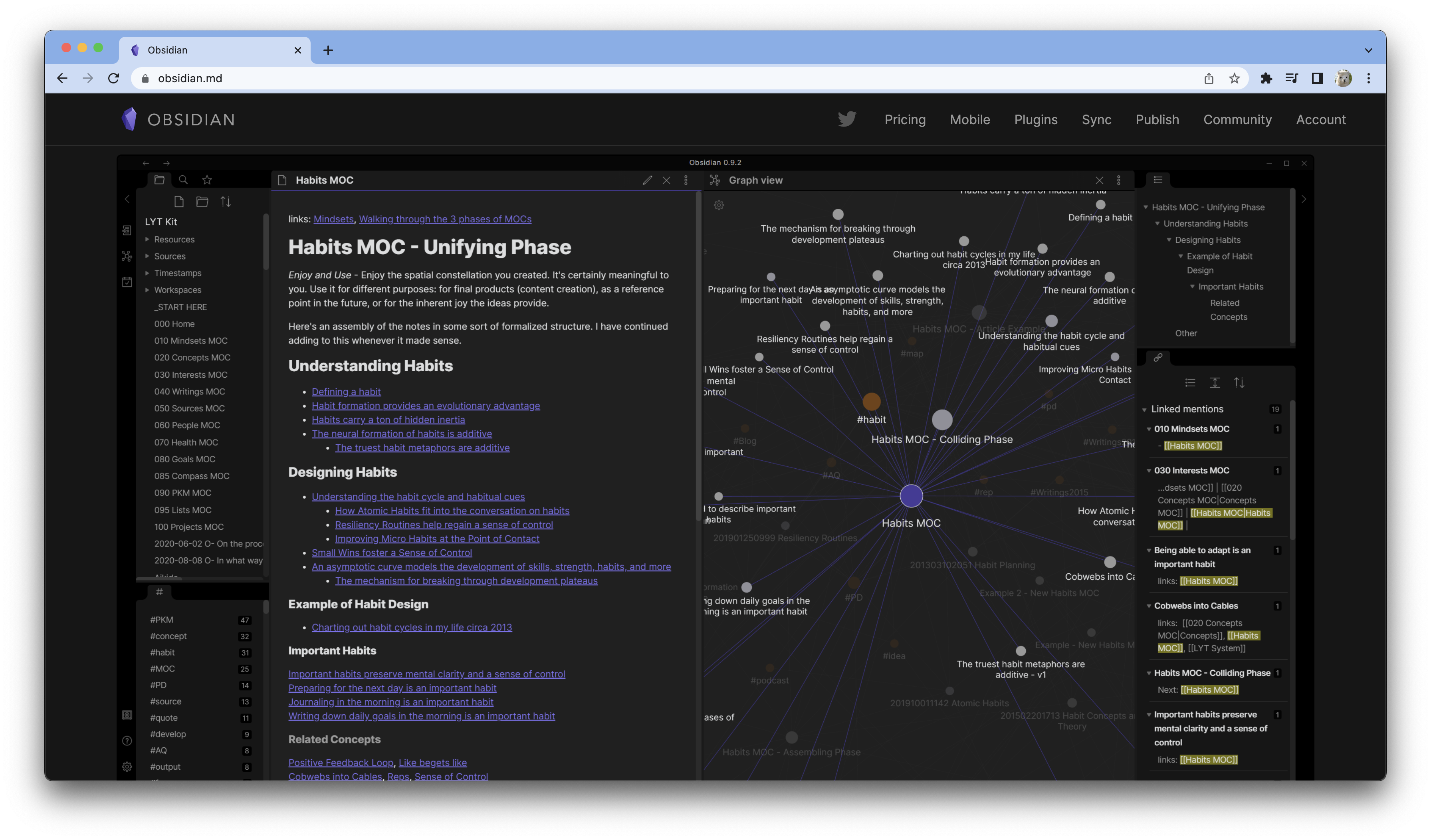
(2) Claude Code - 구조 설계
이제 Obsidian의 저장폴더에서 클로드코드를 활용해서 LLM wiki 구조를 생성합니다. 아래 카파시의 Github을 input으로 주어도 좋습니다. 그리고 나는 어떤 태스크를 수행하려하고, 이 기록의 목적은 무엇인지 상세히 전달해주면 좋습니다.
AI가 정규표현식이나 디렉토리 필터링을 쉽게 할 수 있도록 폴더명 앞에 숫자 접두사(00_, 10_ 등)를 사용하는 것이 좋습니다. 클로드 코드에게 "10번대 폴더만 검색해 줘"와 같이 명확한 지시를 내리기 유리합니다.
LLM Wiki(특히 Karpathy 스타일의 LLM Wiki 계열)에서는 보통 다음과 같은 흐름으로 지식 베이스를 관리합니다.
raw source -> ingest -> structured wiki -> query
↓
lint
↓
postmortemA. Query : wiki에 질의하기
index 검색, 관련 문서 탐색, entity/concept page 로딩, 여러 문서의 내용 종합, 답변 생성, 관련 링크 및 출처 제공과 같은 기능을 담고 있습니다. 예) wiki query "transformer와 diffusion의 차이"
내부 동작은 아래와 같이 이루어집니다.
사용자 질문
↓
관련 page/entity 검색
↓
관련 문서 로딩
↓
내용 synthesis
↓
최종 응답 생성B. ingest : 원본 자료를 wiki로 컴파일
새로운 자료를 위키에 흡수(compilation)하는 작업입니다. 원본 문서 읽기, chunking, 요약 생성, entity/concept 추출, 기존 wiki와 연결, 새로운 page 생성, 기존 page 업데이트, knowledge graph/index 갱신, log 기록과 같은 기능을 포함합니다.
저는 추가적으로 Claude에 아래와 같은 요청을 추가해서 ingest 스킬을 만들었습니다.
"ingest 스킬로 obsidian에 새로운 정보를 수집할 때, 사용자에게 질의를 하도록 해줘.
1) 이 내용을 왜 수집하는지
2) 현재 wiki에 어떻게 연결되는지
3) 저장 가치가 있다고 생각하는 부분이 어떤 포인트였는지"
내부 동작은 아래와 같이 이루어집니다.
Raw Documents
↓
Chunking
↓
Embedding / Extraction
↓
Wiki Knowledge Base예)
wiki ingest paper.pdf
wiki ingest https://arxiv.org/abs/xxxx.xxxxxC. lint : 정합성 검사
깨진 wikilink, orphan page, index 누락, 중복 concept, 오래된(stale) page, metadata/frontmatter 누락, contradiction flag, 너무 긴 page, graph 연결 문제 등을 검사합니다.
D. postmortem : 실패 원인 및 실행 과정 분석 리포트
ingest 실패 분석, hallucination 분석, query failure 분석, agent workflow debugging, retrieval miss 분석, context overflow 분석 등을 진행합니다.
LLM wiki의 폴더 구조는 보통 아래와 같습니다.
raw/ -> 원본 자료
entities/ -> 개별 개념/객체
notes/ -> 중간 정리
synthesis/ -> 통합 분석/고차원 이해특히, synthesis의 경우에는 “LLM이 여러 page를 읽고 새롭게 재구성한 결과물”이라는 의미에서 synthesis라고 부릅니다.
(3) Graphify 설치
Obsidian의 시각화된 Graph를 보면 '이미 Graph 관계성을 갖고 있는데 왜 또 그래프냐?'라고 생각하실 수도 있는데요, 이것은 말그대로 시각화만 이렇게 해둔 것이지 아직은 그래프의 관계성이나 연결관계를 활용해서 답변을 해주지는 못합니다. 문제를 쉬운 말로 바꿔보면 "Graph RAG처럼 LLM wiki를 활용할 수 있는 방법이 있을까" 에 대한 하나의 솔루션이 Graphify와 같은 그래프 데이터베이스를 활용하는 방법이라고 보시면 될 것 같습니다.
pip install graphifyy && graphify install
graphify update D:\Obsidian # 구조만, API 키 불필요, 빠름 (경로는 본인의 폴더 경로로 설정)
graphify extract D:\Obsidian --backend claude # 의미 추출(PDF/이미지 포함)/graphify wiki/ 라는 커맨드를 내리면 wiki폴더 내 파일들을 Graph 형태로 정리하게됩니다.
Graphify는 코드, 문서, PDF, 이미지, 다이어그램 등을 분석해서 지식 그래프(Knowledge Graph) 로 변환해주는 오픈소스 기반 도구입니다. 특히 AI 코딩 에이전트(Claude Code, Codex, Cursor 등)가 대규모 코드베이스를 이해하도록 돕는 목적에 최적화되어 있습니다.
(4) Obsidian 웹 클리핑
Obsidian이 웹 아티클(블로그 글, 뉴스레터, HTML 문서)을 마크다운으로 변환해 vault에 떨굴 때도 있을 겁니다(사실 논문 등의 문서를 주로 대상으로 한다면 필요는 없겠지만). Chrome에 확장기능으로 Obisidian Web Clipper를 추가할 수 있습니다. 물론 그냥 클리퍼로 가져오는 것은 쉽게 할 수 있지만, LLM wiki의 목적에 맞는 템플릿으로 가져오는 것이 더 좋을 겁니다. 이를 위해서 크롬에서 Obsidian Web Clipper의 설정으로 들어가서 기본템플릿을 "내보내기"로 추출해봅시다.
그리고 이것을 CLAUDE에게 제공하면서 "지금 제공한 템플릿은 Obsidian Web Clipper 기본템플릿이야. 이를 참고해서 RAW파일에 있는 지식들을 추출할 수 있는 템플릿들을 만들어줘. LLM wiki로 내가 ingest요청을 했을 때, 구축된 LLM wiki로 쉽게 흡수될 수 있는 구조를 가져야 해. 그리고 필요에 따라 여러개의 json파일을 만들어도 돼" 와 같은 요청을 해서 json 파일들을 만들어냅니다.
Obsidian Web Clipper 설정에서 "들여오기"를 통해서 이 json파일들을 먹여줍니다. 여기서 중요한 것이 import 후 템플릿 순서입니다. Web Clipper는 위에서부터 첫 매치를 쓰므로 Paper → Kaggle → GitHub → Article → YouTube → Generic 순으로 정렬해야합니다. Generic(트리거 없음)이 위에 있으면 안됩니다.
'Agentic AI 활용' 카테고리의 다른 글
| [DeepAgents] DeepAgents란? (0) | 2026.04.25 |
|---|---|
| [Claude] Harness Engineering (0) | 2026.04.17 |
| [Claude] Channel / Dispatch (0) | 2026.04.05 |
| [Claude] Table of Contents (0) | 2026.04.05 |
| [Claude Code] Hook (0) | 2026.03.01 |